Missing files from a newly migrated website – in the 4-6 weeks we had been working on the new site, extra content had been added to the existing production site. We received a database export which included all the new content, but we did not get any of the related files, i.e. attachments and embedded images. The new site went live, and a day into post-launch testing, the missing files issue was found.
We did not have access to the old site via SFTP or SSH, just a login to the WP backend via an IP address, and this would only work by updating our local host file to point to it via the live domain due to some 2FA configuration that was in place.
I logged in and was able to run an export to create an XML file which listed all media which had been added in the last two months.
I tried running an import of the XML file to the new WordPress site, but it failed with the error that the files already existed. I thought this was because I hadn’t switched the local host back or something was stuck in a cache, but in reality it was because the production database already had all the file paths in the wp_postmeta and wp_posts tables.
The new site couldnt import files from the old site using the standard WP tools because it thought the files were already there. No option to overwrite, just a cold hard fail.
The XML export file contained links to all of the files I needed, and so all I needed to do was snag those and put them where they needed to be. Easy!
Luckily the export only had a few hundred files, but I didn’t want to have to get them all manually. I decided to try using Wget to go through the urls in the XML file and download them locally, but Wget retrieves files only via HTTP(S) and FTP(S) so I need a local web server. If I had a local web server set up I could have used that, but I removed it last week with the plan to tidy things up. No worries, lets use the one built in to Python – running this on the command line in the directory where the XML file is starts a Simple HTTP Server using that directory as the web root: python -m SimpleHTTPServer
Now I can use Wget on the local file via http://localhost:8000/
To parse the XML file and grab the files I want, I used the following:
wget -qO - http://localhost:8000/path-to-export-file.xml | parallel --pipe -j4 --round-robin --ungroup 'grep -E -o "https://domain\.tld/[^<]+" | wget -x -v -i - -E'
wget --quiet - turns off output to screen
--output-document - tells wget where to write to - if specified as "-", will write to STDOUT
- http://localhost:8000/path-to-export-file.xml - tells wget which file to get
parallel --pipe -j4 --round-robin --ungroup - use parallel to do this more quickly, useful when dealing with a very lot of files, but not really necessary here. I used it because I wasn't sure how many files I was getting.
grep -E - match the specified pattern
-o - list matching parts of line from XML file
wget -x - force wget to build directory structure for downloaded files
-v - verbose output to terminal
-i - input file - if specified as "-", will read from STDIN
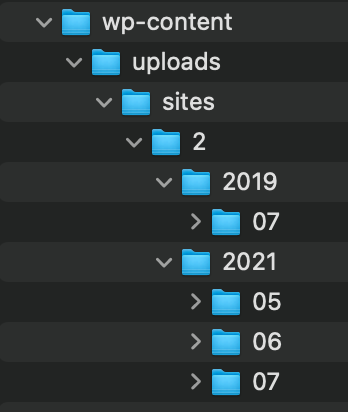
-E - appends .html extension to html pages without an extension. Not required here. This string of commands downloads the xml file, finds all the links in it which start with the specified path, then downloads them locally and recreates structure they exist in on the source site. Once they were all downloaded I was able to just put them where they needed to be to fix the broken links the customer had reported.
I am sure there are other ways to do it, but this quickly achieved the desired result with little effort.
I recently had to work on a site which had archives all the way back…
{kind=link}